With the October 30, 2023 “Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence” from the White House, the safe use of Large Language Models (LLMs) continues to be a hot topic for many public sector agencies. As introduced in our previous post on Large Language Model Applications for Government, LLMs are a form of AI trained on massive amounts of data to understand and respond to natural language instructions called prompts. Primarily used to summarize, translate, and generate text and images, LLMs were popularized with the public release of ChatGPT and DALL-E in November of 2022.
Since many of our government clients are considering the use of LLMs, the GovWebworks AI Lab has been tracking the benefits, risks, and emergent Federal and State guidelines. To facilitate the decision-making process around LLM adoption, we’ve compiled the following primers:
- Understanding LLMs: How LLMs work (see link)
- Risks of Adoption: What to know (see link)
- 9 Gov Tech Use Cases for LLMs: Tools agencies can safely leverage (see this post)
Use Cases for LLMs
Unlike in traditional development, where each step to perform a task is explicitly defined in code, with LLMs we tell the assistant what we want to accomplish using prompts to define the desired outcome. These conversational interfaces can work as a universal interface for applications. Combined with simple drag-and-drop interfaces for composing applications, a new generation of innovation and application development will occur as more individuals within an organization can bring ideas to fruition.
At some point soon, most applications and services will have an LLM integration, for direct use and as plug-and-play for composability with other LLM solutions and autonomous agents. The following LLM root applications are ones we find to be most valuable for our government clients. We include details on how each of these applications work and how risks of adoption can be mitigated.
AI Lab update on the benefits, risks, and emergent guidelines for LLMs in the public sector
Large Language Model Applications for Government
Root applications are those that are supported out of the box by LLMs. Not all LLMs support each type of root application, rather they are building blocks for more complex, composite applications. LLMs and their respective applications covered in this report are multi-modal, which means that in addition to text, they can be applied to files, audio, and video.
- Semantic Search
- Document Understanding
- Content Translation
- Question Answering
- Classification
- Clustering
- Summarization
- Text Augmentation
- Autonomous Agents
1. Semantic Search
Semantic search, also known as natural language search or conversational search, provides users with another way to find content without having to identify keywords. Traditional search, also known as keyword-based search, tries to match the text in a search field (keywords) with words in the search index. This can be problematic because the user must guess at the search terms the content creator used. For example, if a legal document refers to “juvenile”, and a user searches for “children”, the document would not be found.
Semantic search allows users to more easily find content with a similarity search that finds words and concepts that are semantically similar to the word requested. It also empowers building recommendation engines by including “similar” content and documents. In addition to the search capabilities, semantic-based searching can help optimize performance. The results of semantically similar searches can be cached providing fast results for users, especially on mobile.
Semantic search provides the following options:
- Natural Language Search: Replacing existing keyword based search with semantic search capabilities can be as simple as replacing Solr search with a semantic search tool.
- Similarity Search: Similar items can easily be exposed in blocks on a website, for example, to help audiences continue their journey in finding relevant content.
- Recommendations: By storing anonymized search terms as vectors, we can create blocks of similar search terms based on “people who searched for x also searched for y.”
Semantic search is powered by vectors. A vector is a method of representing words as numbers. With vectors, the more similar the word, the closer the numbers. The search terms get converted to numbers as well. In the example below, we can see that the numbers representing ‘fruit’ are close to ‘apple’ and ‘strawberry,’ but further from ‘building’ and ‘car.’ So ‘apple’ and ‘strawberry’ are considered similar and show up in search results.
| Word | Vector Embedding |
| cat | [1.5, -0.4, 7.2, 19.6, 20.2] |
| dog | [1.7, -0.3, 6.9, 19.1, 21.1] |
| apple | [-5.2, 3.1, 0.2, 8.1, 3.5] |
| strawberry | [-4.9, 3.6, 0.9, 7.8, 3.6] |
| building | [60.1, -60.3, 10, -12.3, 9.2] |
| car | [81.6, -72.1, 16, -20.2, 102] |
| Search: fruit | [-5.1, 2.9, 0.8, 7.9, 3.1] |
For semantic/similarity search, you’ll need a database capable of storing vectors. One of the most popular managed services is Pinecone. Alternatively you could host your own vector database such as Weaviate or ChromaDB. In that case, you will need to factor in costs for servers and ongoing maintenance.
2. Document Understanding
Imagine if your audiences and staff could find any document in your organization just by asking for it. Document Understanding, also called Document Intelligence, allows users to ask for documents using natural language. It can then compile answers across all related and relevant documents and cite the appropriate sources. It can also provide a list of additional related documents.

LLMs accomplish this problem by extracting meaning from documents. For example, they can be used to extract information such as the names of people, places, organizations, event dates, monetary amounts, and product names. They can also be used to understand the meaning and purpose of a document, or they can automatically classify and group together related documents. All of this leads to enhanced discovery and find-ability, and an overall improvement to the user experience.
Options include:
- Semantic Document Search: Semantic Document Search is a natural extension of the Semantic Search discussed previously, allowing users to leverage natural language to find documents.
- Entity Extraction: Running documents through an LLM allows extracting entities such as names of people, places, and organizations. It can also extract things like monetary amounts and product names. This can provide the ability for powerful cross referencing of documents.
- PII Redaction: LLMs and other Natural Language Processing tools can be used to redact PII and other sensitive information from documents.
3. Question Answering
Large language model question answering (LLMQA) is a type of natural language processing that uses a LLM to answer questions posed in natural language. It allows audiences to interact with your content, FAQs, and documents in a much more natural way by asking questions and having the LLM provide responses. This can provide higher levels of engagement rather than having to search through content, and it allows a user to just ask questions as they would a domain expert support representative.
Document Question Answering
This is a perfect follow-up application to Semantic Search and Document Understanding, enabling users to ask questions about the contents of the documents in the search results. Instead of having to read through a document (or a set of documents) to find an answer, users can use natural language inputs to ask questions of the documents. For example, with a legal document such as one about a court case, users could ask questions such as, “Who was the plaintiff?”, or “List all individuals involved in this case.”
FAQ Assistant
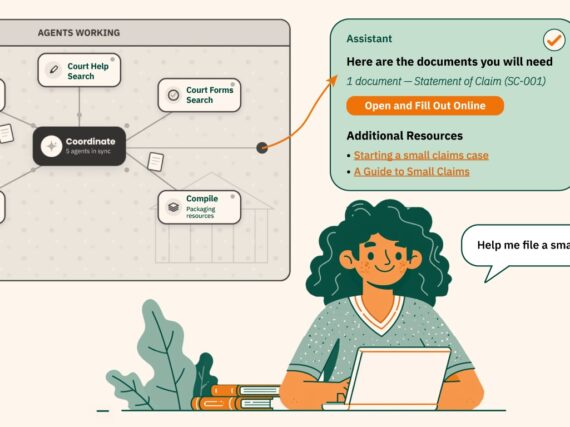
Imagine a large FAQ and self-help section on a judicial department website. Content like this is frequently spread across many categories (breadth) and in many subcategories (depth). This can make it difficult for audiences to find what they need. A FAQ assistant natural language interface would allow users to ask questions about any of the information, including any documents stored there. For example, “How do I apply for a public defender?” The assistant could then summarize results from any relevant source material, providing links to each, as well as providing links to related information such as information on paperwork that needs to be filed and any corresponding forms or documents, information on where to file, and corresponding locations and addresses.

Customer Service Chatbots
A traditionally programmed customer service/support chatbot follows a predefined set of questions, answers, and follow-up questions. For example, the user might select from a list of categories or menu options to funnel it to their desired area of interaction. The chatbot might then present them with additional canned sets of options (also known as a Button Based Chatbot). On the other hand, with an LLM based chatbot, the user can interact with it conversationally. It can automatically identify (categorize) the type of information or action the user is seeking. It can then generate a response from a previously identified corpus of text and media, providing a more natural and engaging interface.
Personalization and Recommendations
LLMs can be used to provide personalized experiences for users based on an understanding of the content being viewed or requested. Think Netflix movie or Amazon product recommendations based on your usage. LLMs along with Generative AI can also automatically assemble additional related information from multiple sources and present it to the user based on user preferences, with citations and links to the source material.
4. Content Translation
Automated content translation allows government agencies to reach a broader audience, especially under-represented minorities, by providing content in multiple languages. Automated services can also reduce costs significantly, as manual content translation can be extremely costly and time consuming.
Types of automated translation include:
- CMS Content Translation: Automated translation can be integrated into content management systems such as Drupal, enabling content creators to automatically translate content into multiple languages at the click of a button. Since errors can occur, workflows and moderation can be implemented to enforce manual review of translated materials. Additionally, automated translation can be applied to media elements such as video transcripts, image captions, and image alt text.
- On-demand Translation: Content can be translated on-the-fly as needed. For example, the translation of form and email submissions from other languages into English.
Some tips to keep in mind for automated translation:
- It’s best to consider automated translations as a starting point. For best quality, having a manual review of translated content can result in higher quality.
- Where possible, using plain language can help ensure smoother, more accurate translations. Niche and domain specific content (such as legal or internal organizational terms) may be more difficult for automated translations. Machine translation services like AWS and Google provide the ability to fine-tune the models used for translation with additional custom words and translations.
- Less popular languages might have a less successful accuracy rate and automated translation may not be appropriate for sensitive content where there is high risk of translation mistakes, for example, a legal document.
5. Classification
Classification is the act of assigning a label to a set of text or media and LLMs can help automate this process. See
Some types of classification include:
- Sentiment Analysis: A LLM can be used to classify text as positive, negative, or neutral. This can be used for tasks such as analyzing customer comments and support emails.
- Topic Classification: Text can be classified into different topics by LLMs for tasks such as organizing documents and media or categorizing search results. It can also be used for automatically organizing and routing webform submissions and support requests.
- Named Entity Recognition: A large language model can be used to identify and classify named entities in text, such as people, places, and organizations. This can be used for tasks such as building knowledge bases and cross linking documents.
- Webform Submission Classification: Say you have a department of conservation that needs to solicit public feedback on area plans. An automated system leveraging LLMs can automatically classify and group the responses into for, and against, based on an analysis of positive or negative sentiment. Additionally, it could group all form-based responses by those that are the same or very similar and based on a form mail type input.
6. Clustering
Unlike traditional methods of manually labeling (classification/ categorization) content or media, clustering uses machine learning to group similar, unlabeled items together.
Prior to LLMs, a common approach to clustering was to use Topic Modeling and algorithms such as Latent Dirichlet Allocation or KMeans, however this approach suffers from a lack of semantic understanding of words. This can result in items in a cluster that do not really belong together.
By utilizing LLMs we get semantic understanding of a word out of the box, allowing the creation of much more accurate clusters, with semantically similar items.
Approaches include:
- Email / Comment Grouping: Consider a government organization, such as a department of conservation or transportation, that has to review public comments from public announcements soliciting feedback on new initiatives (per legal requirements). Oftentimes, large groups of these emails could be chain emails where someone created an initial version and had other people send that email. Clustering can automatically group those emails so they can be represented as a single email chain.
- Related Items: Clustering allows you to easily create blocks of related content and media on websites.
- Generating Embeddings: Depending on the use case, you may need to generate embeddings to measure the relatedness between items. For semantic/similarity search, you could use services like OpenAI GPT to generate the embeddings, either GPT 3.5 or GPT 4, and pay by the token. Or you could use a self-hosted or open-source tool like Weaviate or ChromaDB.
7. Summarization
LLMs can be used to automatically condense a longer piece of text, such as an article, document, or conversation, into a shorter version while retaining its main ideas, key points, and important information.
There are two main summarization approaches:
- Extractive: In this approach, sentences or passages that are deemed most important or representative based on various criteria like sentence relevance, importance, and cohesion, are extracted directly from the original text to form the summary.
- Abstractive: This approach goes a step further by generating new sentences that may not appear in the original text. The AI model comprehends the content of the text and rephrases it in a more concise manner, often using natural language generation techniques. Abstractive summarization can create more human-like summaries but can also be more challenging due to the need for generating coherent and contextually accurate sentences.

Summarization can be used for:
- Documents: Automatically condense lengthy reports, research papers, and documents to extract key findings and insights. These summaries can then include a link to the original document.
- Search: Generate brief summaries for search engine results to help users quickly understand the relevance of a webpage. This can be more effective than traditional search summary methods where just the first x number of characters on the page are used for the summary. That approach doesn’t necessarily represent the actual intent of the page.
- Zoom Meetings: LLM summarization is commonly being used by Zoom to provide a summary of meeting content, including both extractive and abstractive summaries of who said what, and lists of next steps.
8. Text Augmentation
Augmentation provides the ability to transform existing text. For example, you can select a paragraph of existing or in-progress content and then select from predefined augmentation options, such as:
- Tone: Match brand requirements and content guidance with a friendly, professional tone.
- Reading Level: Make sure content is understandable by a broader audience including non-native english speakers.
- Rephrase: Easily try variations of selected text to find a better way of expressing the concept.
- Shorten: Simplify a larger set of text to a shorter, more condensed version while retaining the same meaning.
- Elaborate: Expand on selected text to provide more detail.
Inline Content Augmentation
Text fields in a CMS such as Drupal are now offering the ability to select text and view a dropdown of options for augmenting the content for tone, reading level, rephrase, shorten, and elaborate. This could include a settings screen where preferences are set to influence the augmentation. For example, you could set the tone to match the organization’s branding guidelines for content, and set default reading levels to 8th grade for consumer facing content, and college for professional audiences.
9. Autonomous Agents
Eventually, AI agents may be able to unlock a whole new world of capabilities by autonomously (without human intervention) performing tasks and talking to each other. Imagine an agent that can book appointments for a doctor’s office. You might ask your calendar agent to book an appointment for a physical. It would look up the contact information of your primary physician and communicate with the physician’s agent to schedule a time based on the availability in your calendar and theirs. Composability in the AI agent world centers around the ability to layer these multiple different types of functionality together in sequence as well as in parallel. There are a variety of security risks around wholesale adoption of composability and autonomous agents, so it’s best to proceed with caution in these areas.
In conclusion
Since the AI industry is still in its early stages, expect these applications to evolve and change, often overnight. Always check your state AI guidelines on the use of these applications, as regulations are in flux and can vary state-by-state.
Understanding LLM benefits and risks
See our previous post, Large Language Model Applications for Government, for more details on the benefits and risks of LLMs, and the emergent legal landscape at State and Federal levels.
Schedule a demo
The AI Lab is here to keep our clients updated on the latest changes and recommendations concerning LLMs. For further exploration of these topics, the AI Lab can also help clients identify the right value-based solutions that leverage artificial intelligence for your agency. Whether it’s developing a pilot program or a large-scale integration, we plan and implement solutions that meet business objectives. Contact GovWebworks for a free demo.
Learn more
- Contact GovWebworks to learn more and schedule a free demo
- Subscribe to the GovWebworks AI Lab Newsletter, edited by Adam Kempler
- Blueprint for an AI Bill of Rights from the White House Office of Science and Technology (OSTP)